几年前就想做的分析,因为懒因为忙就一直拖,今年疫情每回老家终于有空可以做一些分析了,结果。。后面再说
图中用到的原始数据及分析代码见githubredpackets;
分析工具为ROOT,安装见root安装介绍
ROOT官网见:ROOT官网:https://root.cern/
整体思路
需要说明一点,在不知道实际策略的情况下使用统计去还原策略,理论上虽然可行,但是却需要大量的数据, 而数据确是整个环节最最难获取的,所以有兴趣的小伙伴欢迎提供数据:
整个的分析过程其实也是很简单的,首先在做之前搜索过相关的资料,发现网络上有一份《微信红包的架构设计》的文档, 里面有提到微信红包的分配策略,读过之后觉得应该靠谱的,所以这个策略可以用来验证统计数据。
1.获取数据
目前获取的数据大部分是群里的真实红包,小部分是自己测试发的红包。获取数据这部分工作是最难的,因为没有相关接口, 需要自己手动统计。还有就是如果希望获取多个人比如五十个,或者一百个这样大群体获取红包的数据,即便是做实验获取样本也非常困难。
微信红包在领取完成后,最上面的小伙伴其实是最后领取的小伙伴,所以按从上到小的顺序记录后最重要把列表反转一下。
2.整理数据
- 数据需要归一化处理,即把获取到的数值归一化到100块,方便不同金额的红包比较
- 统计每个红包手气最佳的索引值,即第几个小伙伴是手气最佳
- 由于每个红包分配的人数也不相同,所以这个索引值也应该归一化,实际采用的方式是归一化到100
- 为了让统计规律更明显,我们优先选择红包发放人数大于等于10人的数据
3.数据分析
原始数据只有64个,筛选数据后数据更少,下面是手气最佳的索引号,已归一化到100。
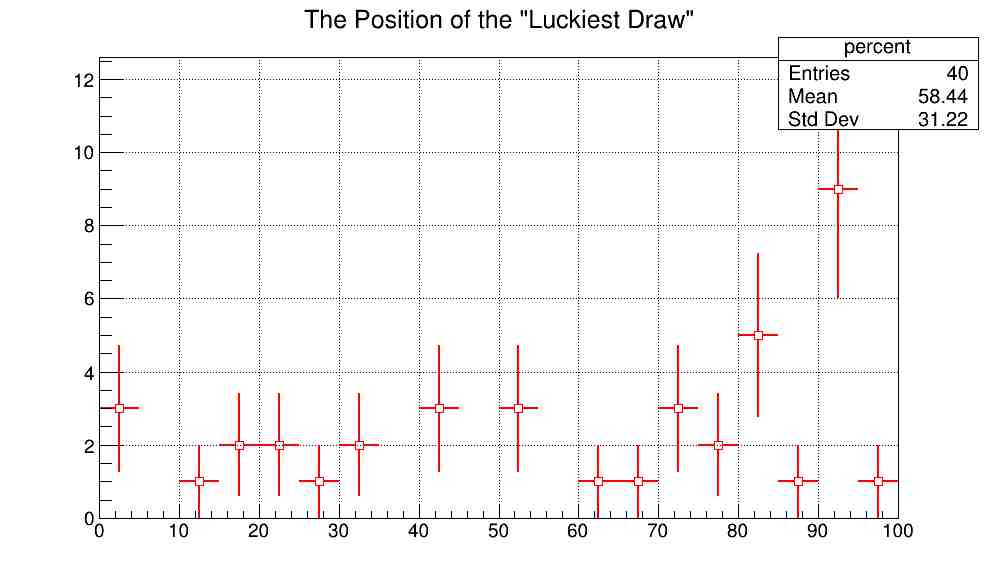
图中直方图数据,只不过用点替代了方格,横轴是索引的百分比,纵轴为数量,图中数据点上的十字是误差棒,表示统计误差, 由于数据量较少,数据的误差普遍较大。
不过依然可以看出手气最佳在百分之九十附近有明显的峰值,即这个附近手气最佳的概率最大。
到这里接下来应该再去分析每个位置的红包分布,以及手气最佳的数值所占当前红包总金额的比重分布等等。 当我把这张图给我对象看并给她解释数据表示的含义的时候,她突然来了一句,这个好像在B站毕导那里看到过。。。。
接写来就是立马打开B站去查找,果然毕导在差不多刚好一年前的这个时候已经做过完全一致的研究。
大意了大意了,虽然在开始之前搜索了互联网上的博文内容,没有发现类似的工作,到头来竟然忽视了还有视频这种东西。 这也导致了对接下来的分析工作没有了兴趣,因为毕导确实都做了,还做的很完整。
分析软件
使用ROOT,关于这个工具有兴趣的可以看下多年前写的安装教程,实际现在不需要这么麻烦:
之所以选用这个工具一是因为熟悉,第二是,实在太了解它的强大了,即便后来做更复杂的数据分析也毫无压力。
原本计划的后续工作
先查看手气最佳的分布,再计算每次抢红包的比重分布。最后用网络上的红包分配方法模拟红包。
(大部分工作毕导都做了o(╯□╰)o)
总结
- 前期调研工作不够充分,科研工作调研是通过查文献,是通过文本搜索,短视频时代的媒介是视频,传统的文本搜索失效了。 所以,视频内容的搜索会不会是未来的一大热点?
- 结论依然是成立的,在红包的结尾有更大的可能为手气最佳
- 更多的工作没有做,比如手气最佳占红包金额的比重,每个位置的期望值等等
- 统计不会说谎,但是统计只对统计有意义,对个体而言,还是赶紧抢,毕竟抢慢了红包都没了,就别扯什么策略了。