现实世界
体验chatgpt4之后,感觉chatgpt4的编码能力较chatgpt3.5有明显提升。主要体现在回复代码更谨慎,这表明它本身具有了评估自己代码水平的能力,不会轻易给出自己也不太确信的代码。 其次chatgpt4给出的代码更自洽,不像chatgpt3.5一样代码本身变量命名都会出现矛盾,有东拼西凑的感觉。最后才是代码质量,给出的代码跟实用的代码相比已经比较接近了,有时候甚至可以直接拿过来使用。
今天我会举一个比较复杂的例子,来演示如何使用chatgpt4编程。 这个例子简化抽象之后用自然语言描述就是:使用ffmpeg读取一个带有alpha通道的图片,然后这张图片与第一路视频融合,融合的效果是只显示alpha通道中不为0的部分。 之后,这部分融合后的视频还需要与另一路背景视频再次融合。
之所以选用这个例子有以下几点考虑:
-
这个功能是我工作中遇到过的,更接近实际。它不是去做leetcode这种看似难实际连搜索引擎都能应付的了的问题,或者说,互联网上没有这个问题的答案。
-
使用C语言,语言足够经典,用户广泛,存量代码多,适用的范围广,对chatgpt也更公平。
-
ffmpeg开源,开源,开源。用户量大,有广泛的社区支持。
-
我熟悉,我会,我做过,我可以当好裁判。
现在我用图片的方式来具体描述这个任务:
有一张图片mask.png, 尺寸大小1080p,只有中间椭圆部分是不透明的,其余都是透明的。看起来这样:

有一个1080p的视频文件video.mp4,看起来这样:

一个2160p的视频做背景,文件名background.mp4,视频内容看起来这样:

任务的目的就是先把图片mask.png与video.mp4融合变为这样, 透明的地方不显示,只显示原来图片中椭圆部门:

然后把这个结果覆盖到背景视频上变成这样:

下面我们来用chatgpt求解
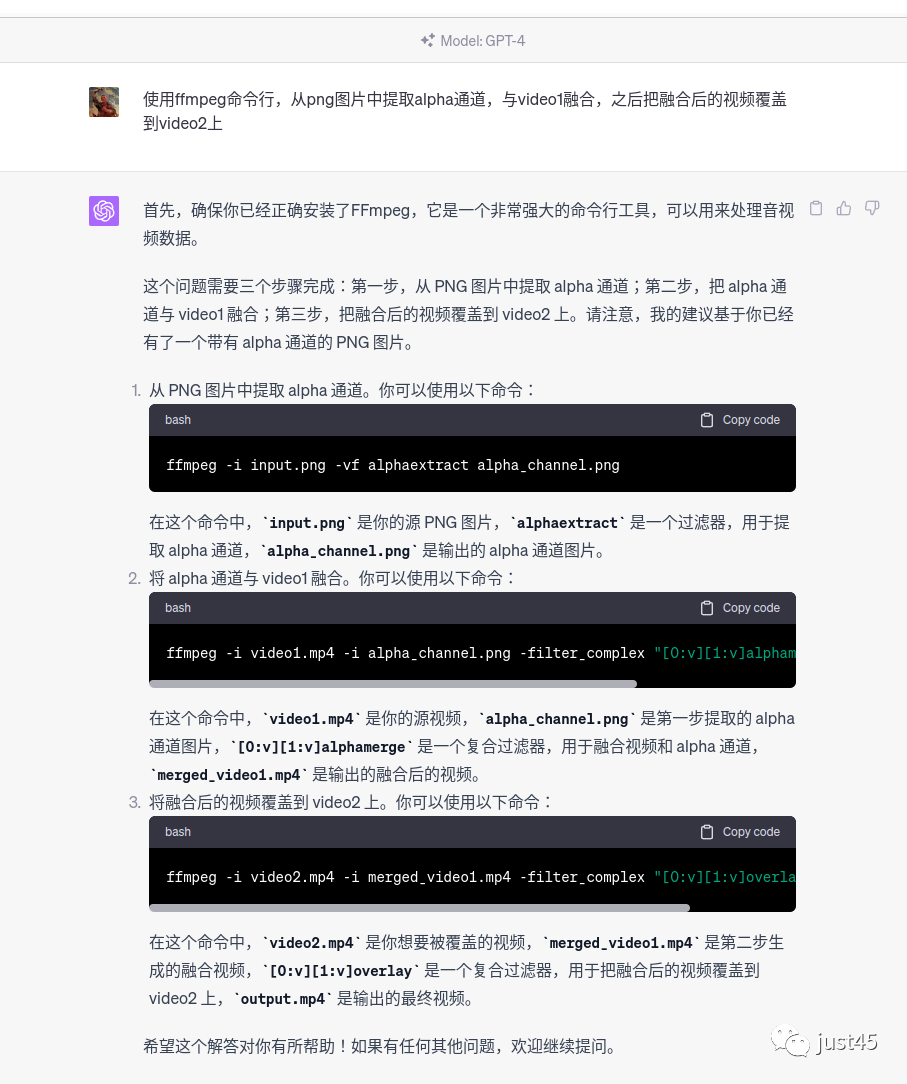
chatgpt使用了分步操作,当然他的步骤是正确的。还可以要求他使用一行命令行,而不是多行。
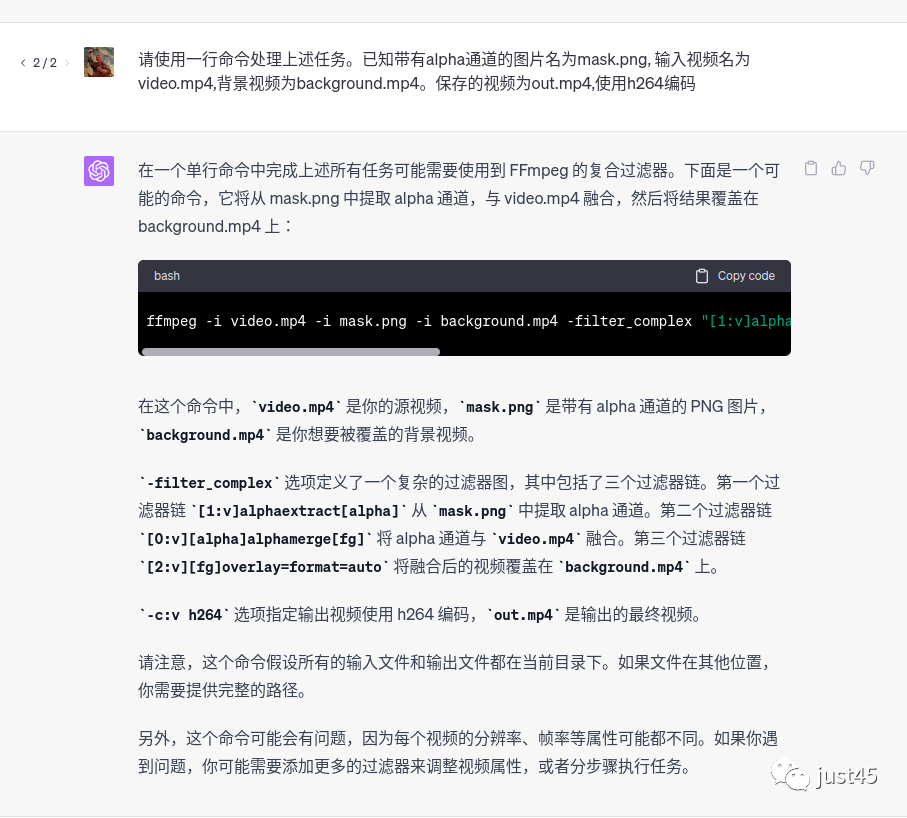
把chatgpt-4的代码部分单独拿出来放在这里:
ffmpeg -i video.mp4 -i mask.png -i background.mp4 -filter_complex "[1:v]alphaextract[alpha];[0:v][alpha]alphamerge[fg];[2:v][fg]overlay=format=auto" -c:v h264 out.mp
这个结果令人惊喜,复制到命令行后也可以直接运行并给出运行结果,而且这个结果已经接近标准答案。
当然还不够,因为命令行方法是无法集成到工程中的。好在ffmpeg开源,“源码面前,了无秘密”,如果正向去分析ffmpeg的执行过程, 理论上也是可以获取处理的整个流程的,但实际上这个工作量很庞大,需要耗费很多精力。但无论如何,能到这一步,chatgpt已经给出了解决方案,而且这个效率要远高于搜索引擎。
我们对chatgpt提出更多的要求:

chatgpt-4写代码要比chatgpt3.5谨慎很多,使用chatgpt3.5时,它会给出一大串代码,但这些代码基本都无法使用,比如各种变量不统一,出现莫名其妙的函数。chatgpt-4的谨慎,说明它自己已经有了一定的评估能力,知道自己代码的可靠程度。如果chatgpt-4毫不犹豫地给出代码,多半这时候的代码是比较靠谱的。
这个功能略复杂,假设我不是一个对ffmpeg完全陌生的新手,只是滤镜这部分不熟悉,只要ffmpeg给出滤镜部分的代码,也就是第4条:
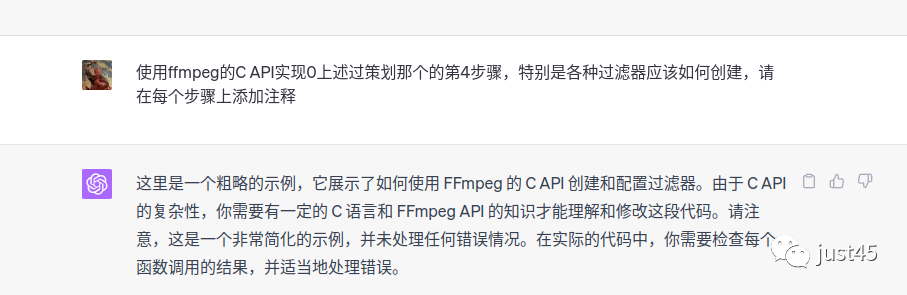
代码部分如下:
#include <libavcodec/avcodec.h>
#include <libavformat/avformat.h>
#include <libavfilter/avfilter.h>
#include <libavfilter/buffersink.h>
#include <libavfilter/buffersrc.h>
// ...
// 假设输入视频上下文 (AVFormatContext) 和输出视频上下文已准备好。
// 获取过滤器图API。
AVFilterGraph* filter_graph = avfilter_graph_alloc();
// 定义过滤器描述。
const char* alpha_extract_description = "alphaextract";
const char* alpha_merge_description = "alphamerge";
const char* overlay_description = "overlay";
// 创建过滤器。
AVFilterContext* alpha_extract_ctx;
AVFilterContext* alpha_merge_ctx;
AVFilterContext* overlay_ctx;
// 从PNG中提取alpha。
const AVFilter* alpha_extract = avfilter_get_by_name("alphaextract");
avfilter_graph_create_filter(&alpha_extract_ctx, alpha_extract, "alpha_extract", alpha_extract_description, NULL, filter_graph);
// 合并alpha通道和视频。
const AVFilter* alpha_merge = avfilter_get_by_name("alphamerge");
avfilter_graph_create_filter(&alpha_merge_ctx, alpha_merge, "alpha_merge", alpha_merge_description, NULL, filter_graph);
// 叠加到背景视频上。
const AVFilter* overlay = avfilter_get_by_name("overlay");
avfilter_graph_create_filter(&overlay_ctx, overlay, "overlay", overlay_description, NULL, filter_graph);
// 将过滤器链接在一起。
avfilter_link(alpha_extract_ctx, 0, alpha_merge_ctx, 0);
avfilter_link(alpha_merge_ctx, 0, overlay_ctx, 0);
// 将过滤器链连接到缓冲源和缓冲汇。
AVFilterContext* buffersrc_ctx;
AVFilterContext* buffersink_ctx;
// 创建并链接缓冲源。
const AVFilter* buffersrc = avfilter_get_by_name("buffer");
avfilter_graph_create_filter(&buffersrc_ctx, buffersrc, "buffersrc", "video", NULL, filter_graph);
avfilter_link(buffersrc_ctx, 0, alpha_extract_ctx, 0);
// 创建并链接缓冲汇。
const AVFilter* buffersink = avfilter_get_by_name("buffersink");
avfilter_graph_create_filter(&buffersink_ctx, buffersink, "buffersink", NULL, NULL, filter_graph);
avfilter_link(overlay_ctx, 0, buffersink_ctx, 0);
// 配置过滤器图。
avfilter_graph_config(filter_graph, NULL);
// ... 这里应该是读取,解码,发送到过滤器,从过滤器接收,编码和写入的循环。
这段代码基本把filter的使用流程展示出来了,但是不够完整。我们这里有三个输入,应该有三个buffersrc的过滤器,但实际只有一个。这里显示出了chatgpt4的不足,它自己还不足以完成功能,如果我对filter一无所知,我是看不出这些问题的。但如果我运行这段代码,必然会提示错误,逻辑上我也可以在报错之后继续追问,让chatgpt自行修改。
现在我指出chatgpt的错误,让他自行改正:
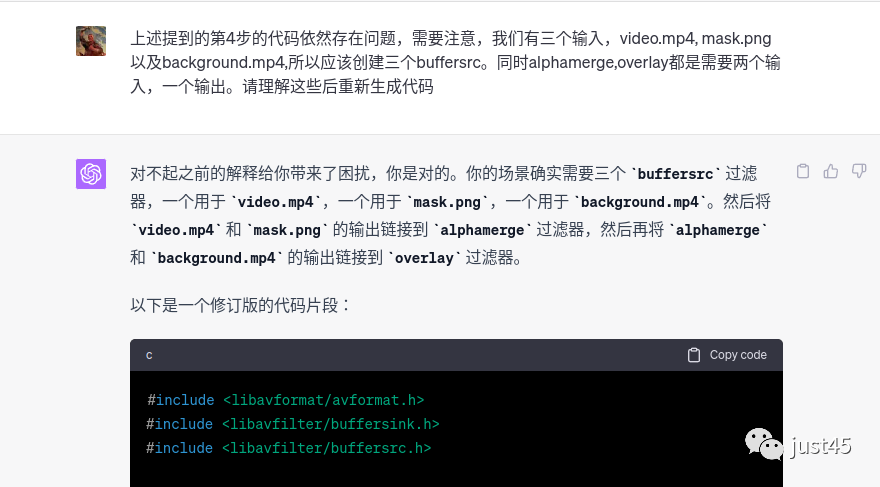
为了方便阅读,我们代码放在这里:
#include <libavformat/avformat.h>
#include <libavfilter/buffersink.h>
#include <libavfilter/buffersrc.h>
// 创建过滤器图
AVFilterGraph *filter_graph = avfilter_graph_alloc();
// 加载 "alphaextract" 过滤器,并添加到过滤器图中,它用于提取 PNG 图片的 alpha 通道
const AVFilter *alphaextract_filter = avfilter_get_by_name("alphaextract");
AVFilterContext *alphaextract_ctx;
avfilter_graph_create_filter(&alphaextract_ctx, alphaextract_filter, "alphaextract", NULL, NULL, filter_graph);
// 加载 "alphamerge" 过滤器,并添加到过滤器图中,它用于合并 alpha 通道和视频
const AVFilter *alphamerge_filter = avfilter_get_by_name("alphamerge");
AVFilterContext *alphamerge_ctx;
avfilter_graph_create_filter(&alphamerge_ctx, alphamerge_filter, "alphamerge", NULL, NULL, filter_graph);
// 加载 "overlay" 过滤器,并添加到过滤器图中,它用于将合并后的视频覆盖在另一视频上
const AVFilter *overlay_filter = avfilter_get_by_name("overlay");
AVFilterContext *overlay_ctx;
avfilter_graph_create_filter(&overlay_ctx, overlay_filter, "overlay", "format=auto", NULL, filter_graph);
// 加载 buffersink 过滤器,它用于从过滤器图中获取过滤后的帧
const AVFilter *buffersink_filter = avfilter_get_by_name("buffersink");
AVFilterContext *buffersink_ctx;
avfilter_graph_create_filter(&buffersink_ctx, buffersink_filter, "buffersink", NULL, NULL, filter_graph);
// 加载三个 buffersrc 过滤器,用于将三个源的帧输入到过滤器图中
const AVFilter *buffersrc_filter = avfilter_get_by_name("buffersrc");
AVFilterContext *video_src_ctx, *mask_src_ctx, *bg_src_ctx;
avfilter_graph_create_filter(&video_src_ctx, buffersrc_filter, "video_src", NULL, NULL, filter_graph);
avfilter_graph_create_filter(&mask_src_ctx, buffersrc_filter, "mask_src", NULL, NULL, filter_graph);
avfilter_graph_create_filter(&bg_src_ctx, buffersrc_filter, "bg_src", NULL, NULL, filter_graph);
// 将过滤器连接起来,以形成过滤器链
avfilter_link(mask_src_ctx, 0, alphaextract_ctx, 0);
avfilter_link(alphaextract_ctx, 0, alphamerge_ctx, 0);
avfilter_link(video_src_ctx, 0, alphamerge_ctx, 1);
avfilter_link(alphamerge_ctx, 0, overlay_ctx, 0);
avfilter_link(bg_src_ctx, 0, overlay_ctx, 1);
avfilter_link(overlay_ctx, 0, buffersink_ctx, 0);
// 初始化过滤器图
avfilter_graph_config(filter_graph, NULL);
到这里为止,代码依然有错误,主要有两个,首先是我虽然称呼为buffer src过滤器,其实ffmpeg代码中并没有buffersrc过滤器, 只有buffer过滤器。见上述代码29行。其次buffer src类型过滤器创建时应添加参数,chatgpt没添加。关于这两个问题我们继续提问:
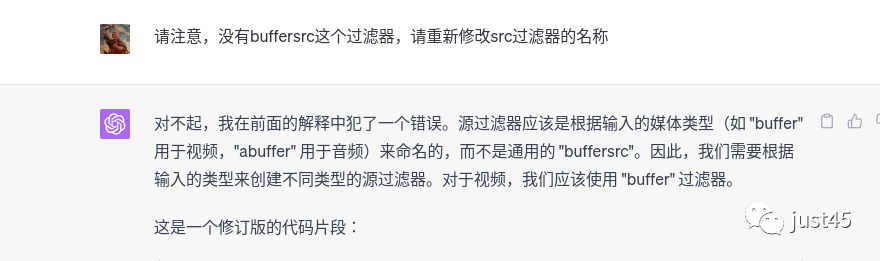
在这一步,chatgpt成功修改buffersrc为buffer。
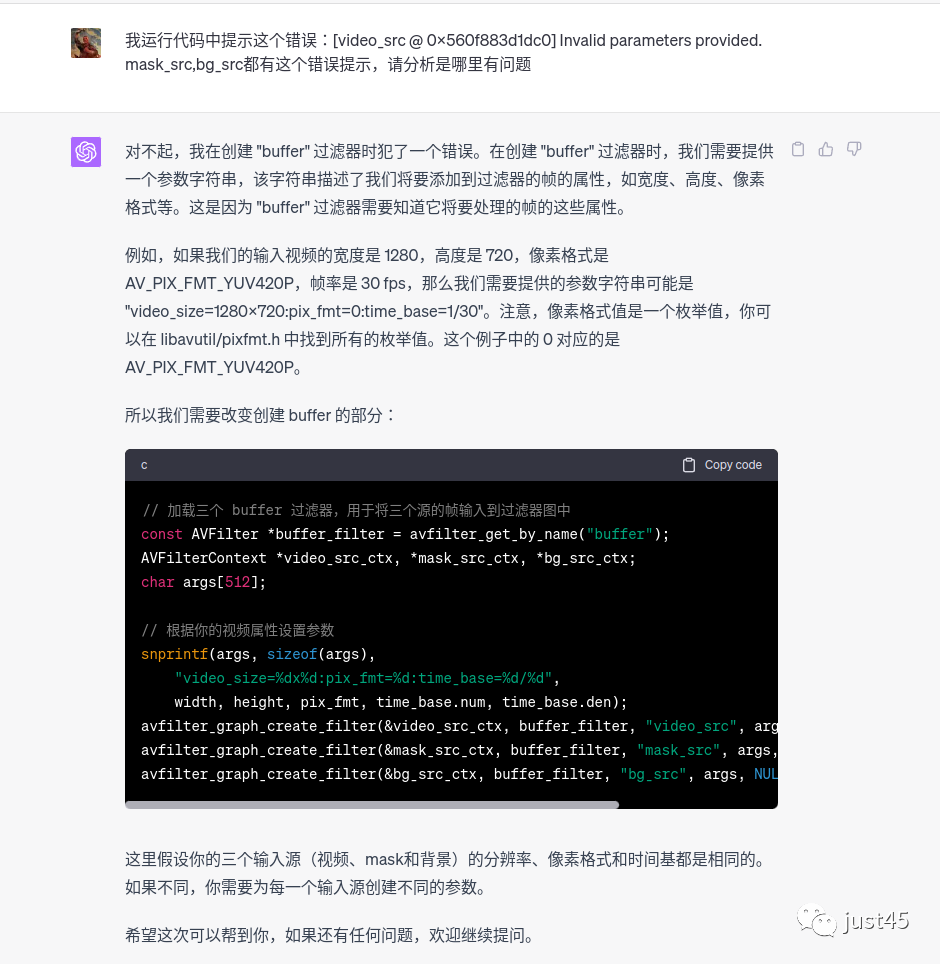
我把chatgpt因未提供参数,导致运行时出现的错误反馈给chatgpt,它也可以成功修复:

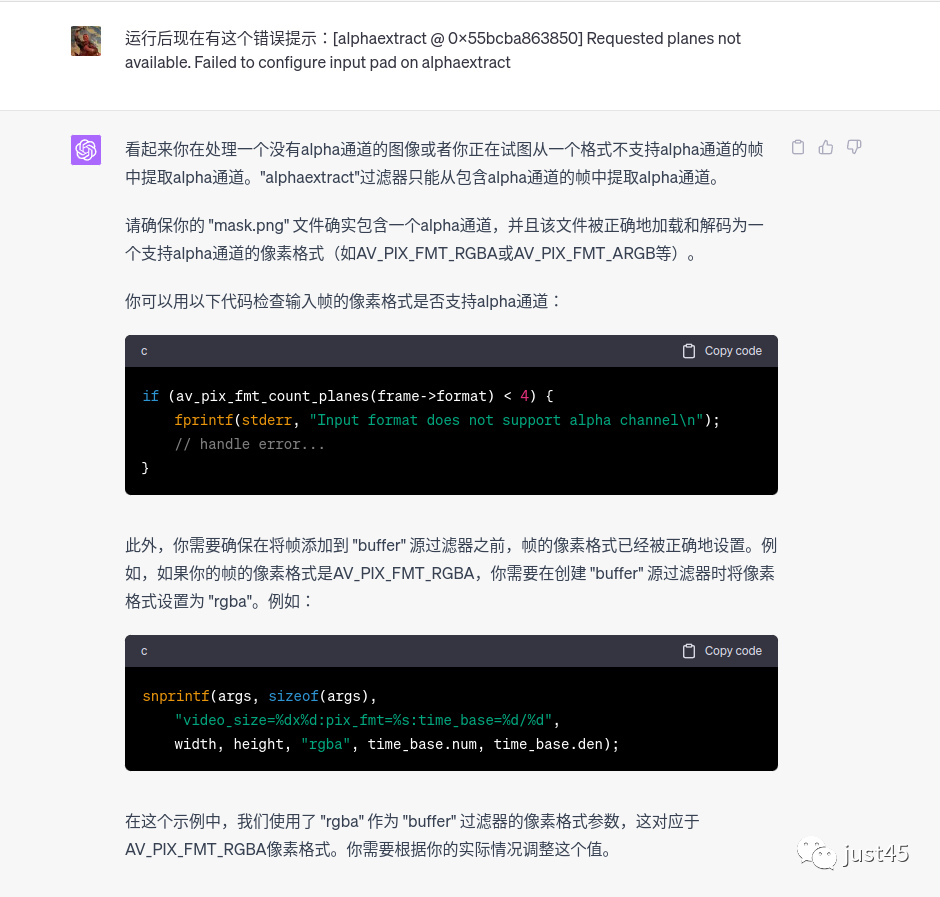
这里依然有错误,因为png图片是rgba像素格式,视频是yuv420格式,两者不应该使用同一个args的参数,反馈给chatgpt让他改正。
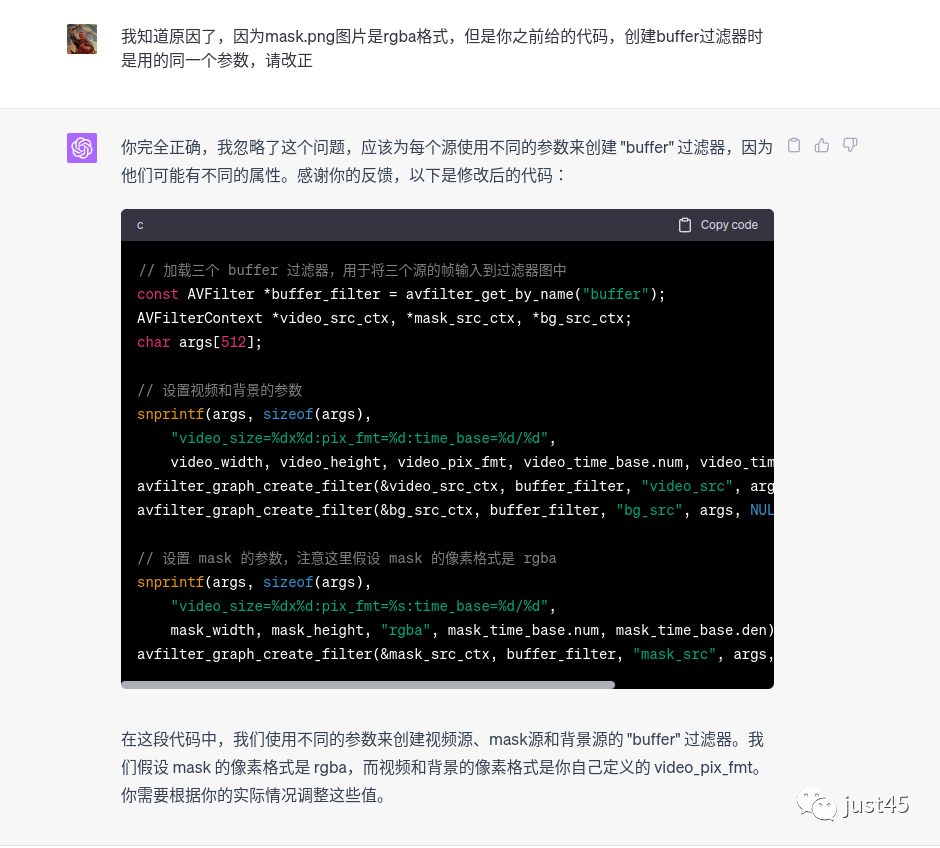
到目前为止filter部分的功能已经完成,我补足读取以及发送数据到filter的代码,尝试运行。
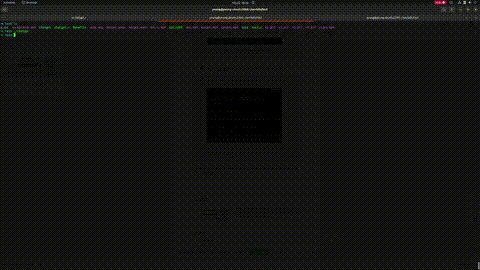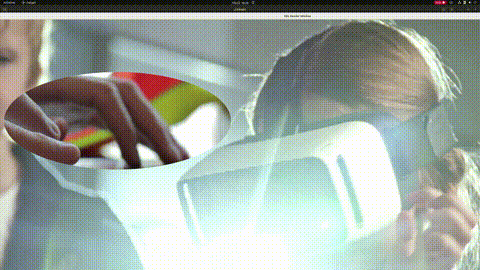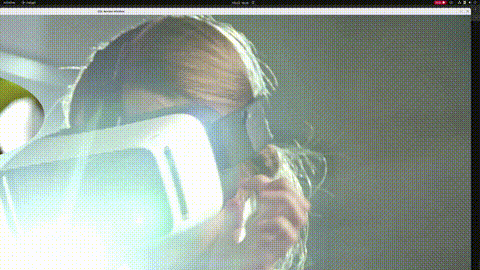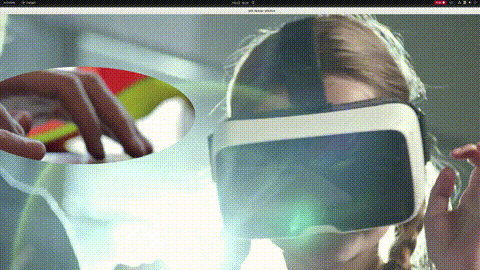
效果达成。(这里为了简单,所有工作都在一个线程内,且没有启用硬件解码,所以会有点卡顿,由于我的显示器是2k显示器,所以无法完整显示4k视频。)
使用建议
目前来看chatgpt4依然只能作为辅助编程。chatgpt3.5时,它像一个不识字但是可以看着原文填空的小孩子,到chatgpt4时, 它已经能够理解题目的意思,但还不是很会做题,就像当年我们期末考试没考课后习题就不会做一样。 但在我们可以介入的情况下,它依然可以极大提高我们的开发效率,更重要的是还可以拓展我们的思路,给出意想不到的方法。
如果我们有足够的时间,甚至可以让chatgpt完成工作的每一个步骤,然后我们依次验证,报错,让chatgpt修改,再验证。 想学习新内容或知识点的话也可以让chatgpt给出学习资料,参考书籍。在大多数情况,chatgpt都可以作为我们入门某个技术栈的技术顾问,而且是那种不厌其烦可以刨根问底地追问的顾问。 但是他的缺点同样致命,他回答问题的时候无法给出答案的置信度,即便他的回答是错的,他也是一副斩钉截铁的态度, 果真就是一本正经胡说八道,如果我们指出他的错误,他又会立马承认错误。这导致我们无法百分百分相信他的每一个回答。
未来世界
chatgpt到此为止了吗?显然不是。在我们的例子中,程序员是作为一个测试者,不断反馈出报错信息让chatgpt修改,然后再验证,再修改。 但是这种工作,分明chatgpt自己就可以做。如果chatgpt既扮演自己,又扮演测试者,然后不断试错,不断改正,是否就可以完成任何工作? 统治世界,它甚至都不需要到产生自主意识的阶段,只需要一两个疯狂人类的助攻就可以了——技术一定会被滥用,就像电脑病毒,就像基因编辑。
chatgpt或许永远不能达到人类一样的思维高度,但人类也并未证明人类思维是宇宙的最优解,说不定机器思维更适合未来世界? 无论如何,潘多拉魔盒确实已经开启,在这个竞争时代,任何妄图限制,影响,阻碍这项技术发展的行为都注定是徒劳的。 深处时代变革之初的我们,或许只能等到多年以后面对机器大军的时候,才会回想起2022年末openai发布chatgpt的那个遥远的下午……